Muitas pessoas acham que uma pesquisa é um "retrato" da vontade eleitoral do país.
Bem, isto não é inteiramente verdade. A analogia do saco com moedas é muito boa para representar uma cidade ou um agrupamento de pessoas. Mas na medida que há diversos destes agrupamentos, então algumas diferenças com o modelo de um saco de moedas começam a aparecer.
Neste caso, o melhor é um modelo com múltiplos sacos de moedas. Ainda assim, a coisa é complicada. Há cidades, vilas e estados a serem levados em considerações. Aí, o melhor modelo é o de múltiplos sacos de moedas.
O que se está interessado neste caso é estimar a proporção entre moedas de dois tipos no total de sacos. Como os sacos terão tamanhos diferentes, e portanto número de moedas diferentes, esta particularidade pode ser levada em conta considerando pesos diferentes para cada um dos sacos. Assim, os sacos maiores ficam com maior peso e os menores com menor peso.
Cada um dos sacos tem uma proporção diferente. No final o que desejamos é a proporção total - ou seja do conjunto total de moedas em todos os sacos.
Para simplificar, vamos considerar 2 sacos apenas. O primeiro tem uma proporção pa (para moedas do tipo 1) e o segundo tem uma proporção pb (para moedas do tipo 1). Ao mesmo tempo, o saco A tem Na moedas no total e o saco B tem Nb moedas no total. O número total de moedas é Na+Nb.
Assim, o número total de moedas do tipo 1 será:
N1=pa*Na+pb*Nb
E o número total de moedas do tipo 2 será:
N2=(1-pa)*Na+(1-pb)*Nb = Na+Nb-(pa*Na+pb*Nb)= Na+Nb - N1
Se dividirmos estes valores pelo número total de moedas teremos:
p1=N1/(Na+Nb)=pa*Na/(Na+Nb)+pb*Nb/(Na+Nb)
p2= 1-N1/(Na+Nb) = 1-p1
Esta tudo muito legal, mas e quando temos apenas uma estimativa dos valores de pa e pb?
Neste caso teremos:
pa'-da
Assim teremos:
(pa'-da)*Na
<(pa'+da)*Na
Podemos somar os dois (todos são positivos) e teremos:
(pa'-da)*Na+(pb'-db)*Nb
<(pa'+da)*Na+(pb'+db)*Nb
Podemos chamar de N1' =pa'*Na+pb'*Nb e N1/(Na+Nb) = p1'
Então teríamos:
N1'-(da*Na+db*Nb)
Dividindo pelo número total de moedas teríamos:
p1'-(da*Na+db*Nb)/(Na+Nb)
Assim, a incerteza é: (da*Na+db*Nb)/(Na+Nb).
Chamando: Na/(Na+Nb) = psa e Nb/(Na+Nb) = psb = 1-psa
Temos que a incerteza é:
d=psa*da+(1-psa)*db = psa*da+psb*db = psa*(da-db) +db
Repare que se da for igual a db, então a incerteza é db. Isto na realidade não é estranho. Mas soa esquisito...
Porque?
Vamos supor que tivéssemos juntado os dois sacos em um só e tirado de lá. Certamente, se eu tiro Nx do saco eu tenho uma incerteza dx. Mas para termos a mesma incerteza em cada saco eu deveria tirar Nx do saco 1 e Nx do saco 2. Ora, eu tirei então um total de 2* Nx moedas. Então certamente se tudo estivesse em apenas 1 saco, eu precisaria de menos moedas retiradas para ter o mesmo grau de confiança.
Mas seguimos em frente. No caso de uma eleição em um país como Brasil a coisa fica mais complicada ainda. A razão é que temos uma dispersão populacional. Em outras palavras, ao realizarmos nossas amostras somente nas cidades, estamos cometendo um erro.
Que erro? O erro é que não estamos considerando todos os saquinhos de moedas, apenas os maiores. Isto pode ser uma aproximação boa ou má, dependendo das proporções envolvidas. Um exemplo de onde isto pode dar errado é o caso da região centro oeste.
As 10 maiores cidades constituem cerca de 50% da população. O restante está pulverizado entre cidades substancialmente menores. O equivalente a isto é ao invés de realizar a amostragem nos dois saquinhos, realizar apenas em 1.
Qual será o erro? Agora não temos nenhuma informação sobre o saco b, então:
Ou seja tudo que podemos dizer é que <0
<1
Somando temos
(pa'-da)*Na
<(pa'+da)*Na+Nb
ou:
(pa'-da)*psa<(pa'+da)*psa+psb
Note que o tamanho do que foi deixado de fora (psb) irá determinar em última análise o erro. E este erro é difícil de consertar...
Uma conseqüência lógica desta teoria é em regiões mais homogêneas, a pesquisa deve funcionar melhor.
Mas vamos entrar neste detalhes em um futuro post






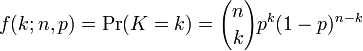
![\operatorname{E}[X] = np](http://upload.wikimedia.org/math/4/7/0/470417702b45747e83aa8e85f8320cbc.png)
![\operatorname{Var}[X] = np(1 - p).](http://upload.wikimedia.org/math/6/9/1/6911427653233b5f214b3116dbe505c2.png)



